

Zero-ETL: Nếu một ngày Data Engineer không còn giá trị?!
Bài viết lần này mình sẽ đề cập đến Zero-ETL, đây là 1 buzzword mới nổi gần đây. Hãy cùng mình phân tích xem liệu Zero-ETL có thay thế được Data Engineer như kỳ vọng hay những lời quảng cáo ?!

Disclaimer: Bài viết chia sẻ theo trải nghiệm cá nhân, không promote bất cứ sản phẩm nào được đề cập đến trong bài viết.
Trong sự kiện AWS re:Invent tại Las Vegas tháng 11/2022 vừa rồi, AWS CEO Adam Selipsky có giới thiệu Zero-ETL integration với khả năng sao chép dữ liệu từ Aurora sang Redshift (2 services này đều của AWS) mà không cần thiết lập ETL pipelines phức tạp, vị CEO cũng chia sẻ: Đây sẽ là bước đi đầu tiên để tiến đến loại bỏ hoàn toàn ETL pipelines trong tương lai

“But what if we could do more? What if we could eliminate ETL entirely? That would be a world we would all love. This is our vision, what we’re calling a zero ETL future. And in this future, data integration is no longer a manual effort,” Adam Selipsky
Theo TechCrunch, xử lý dữ liệu là 1 điều rất rất khổ sở với Data Scientist và data team, nếu áp dụng service này từ AWS, thì có thể ngầm hiểu (implicitly) là data scientist không cần phải thông qua data engineer hay công ty phải build 1 team data đồ sộ để quản lý các ETL pipelines phức tạp, mà họ (data scientist) có thể trực tiếp truy vấn/phân tích dữ liệu từ data source nhanh nhất có thể. Nghe thì cũng hay đấy, cộng đồng Data Engineering sôi sục cả lên như ChatGPT, chủ yếu xoay quanh 2 vấn đề chính sau:
Có thực sự xóa bỏ hoàn toàn ETL pipelines( hay còn gọi là data pipelines)
Nếu thực sự xóa bỏ được ETL, vậy nó có dẫn đến xóa bỏ luôn cả role Data Engineer
Hãy cùng mình phân tích từng vấn đề nhé!
I. Zero-ETL là gì?
Là bất cứ cái gì liên quan đến ETL đều bị loại bỏ hết đó mấy ông, cái tên của nó nói hết rồi còn gì. Trong ngữ cảnh của AWS, họ đề cập đến Zero-ETL “Integration”, tức là bạn không cần phải (hoặc ít nhất) xây dựng data pipeline để chuyển dữ liệu từ nơi A sang nơi B, C, D … Mọi dữ liệu sẽ được tự động sao lưu trong thời gian nhanh nhất (near real-time) đến nơi người dùng cuối sử dụng trực tiếp. Lưu ý: Phương pháp này gọi là “copy -based integration“, mình sẽ phân tích cái không tốt của phương pháp này ở các phần sau
Nhưng điều mình muốn nói ở đây, đó là, đây không phải là 1 khái niệm gì đó mới. Trước AWS, Google, Databricks, hay Microsoft đều có những dịch vụ quảng cáo là Zero-ETL trước rồi. Trong phần bên dưới, mình sẽ đề cập đến việc ứng dụng Zero-ETL integration và để xem thực sự AWS có làm điều gì đột phá?
II. Xóa bỏ ETL pipeline, liệu có thực tế?
Phương pháp nào cũng cũng có điểm tốt và chưa tốt, trước khi đi vào đánh giá điểm chưa tốt, mình vẫn có lời khen về các điểm tốt mà phương pháp này mang lại
Tốt:
Tốc độ: Nếu bạn đang/từng xây dựng datalake hoặc lakehouse, data layer đầu tiên (hay còn gọi là landing zone) là nơi thu thập raw data từ nguồn. Đặc điểm của layer này là không xử lý (manipulation) gì cả, chỉ đơn giản là copy thôi. Vì thế, Zero-ETL đặc biệt hữu ích trong trường hợp này, đỡ mất thời gian data team phải ngồi viết những pipeline để extract data từ nguồn. Với kinh nghiệm riêng của mình, cũng phải hơn 60% pipeline mình viết chỉ đơn thuần là Extract-Load (E-L)
Cải thiện tính toàn vẹn dữ liệu từ nguồn: Ủa, viết cái pipeline đơn thuần là copy (E-L) dữ liệu từ nguồn thôi mà cũng sai là sao mấy cha nội Data engineer? Nói ra thì mang nhục chứ nhiều thứ không lường trước được vẫn gây ra lỗi (data loss, wrong conversion, connection issues…). Nói chung, cái gì mà con người dev thì sẽ có bugs. Vì thế, những việc đơn giản như Extract và Load nên để máy làm cho khỏe
Chê:
Ủa rồi chữ “T“ trong E-T-L đâu? Như đã phân tích ở mặt tốt, Zero-ETL chỉ thích hợp áp dụng ở landing zone, nhưng còn ở những layer về sau (enrichment layer, semantic layer) là nơi mà data scientist/analyst sử dụng dữ liệu cho Machine Learning models, thì các Transform operation sử dụng rất nhiều. Hiện tại vẫn chưa thấy AWS nêu giải pháp cho vấn đề này. Cá nhân mình nghĩ, phần Transform trong ETL là phần quan trọng nhất và tạo ra nhiều giá trị nhất trong ETL value chain. Sau đây là các trường hợp cơ bản mà giải pháp Zero-ETL chưa thể làm tốt thay cho data pipeline hiện nay

Với các data pipeline có dependency cao giữa các tables, ở ví dụ trên là external table với source table có tốc độ (velocity) thay đổi dữ liệu khác nhau, sẽ rất khó để áp dụng Zero-ETL để đồng thời tạo ra được destination table
Naming conventions: Với bạn làm làm việc ở các nước không nói tiếng Anh, việc dịch tên cột sang tiếng Anh, chưa kể còn phải chuẩn hóa (standardization) cho đồng nhất tên gọi trong 1 database. Đó là 1 phần trong Transform dữ liệu, nhưng Zero-ETL chưa giải thích rõ ràng vấn đề này

Trường hợp này khá là nguy hiểm. Khi hiện nay business logics thay đổi rất nhanh, nhiều measures trong Fact table phải thay đổi (transform) theo liên tục bởi data scientist/analyst, thì phương pháp “copy-based integration“ của Zero-ETL không giải quyết được
Như bài viết trước mình có đề cập Data Modeling vô cùng quan trọng cho Modern Analytics, việc thay đổi data model từ data analyst hay analytics engineer sẽ có thể sinh ra các entity tables mới. Zero-ETL cũng không giải thích luôn làm sao từ Source Data có thể tự extract ra được các entities mới
Data Quality: Nếu dữ liệu từ Source Data tệ và không được kiểm soát tốt, việc sử dụng Zero-ETL để đưa dữ liệu nhanh nhất đến người dùng cuối chỉ làm tệ thêm vấn đề. Chính vì vậy transform raw data sang các layer khác nhau nhằm mục đích phòng thủ/củng cố thêm chất lượng dữ liệu
Vendor Lock-In: Rồi giả sử nếu AWS có thể giải quyết được hết các vấn đề của ETL pipeline truyền thống(chí ít là các vấn đề mình đưa ra ví dụ), điều mà mình tin AWS hoàn toàn có thể làm được. Thì chẳng phải toàn bộ data/platform infrastructure của bạn đều lệ thuộc vào AWS à. Nếu downtime/disaster xảy ra ở nơi đặt data center của AWS thì sao? Là 1 data architect/engineer, liệu bạn có xây dựng kiến trúc có ‘Achilles’ heel’ - single point of failure
Transferring Data Cost: Không có bữa trưa nào miễn phí. Cái gì nghe tiện lợi đều phải đánh đổi với 1 cái giá nào đấy, nhất là các cloud providers lợi dụng tối đa làm tiền data transfer service. Nghĩ kỹ trước khi trình budget lên Heads/C-level nhé




III. Zero-ETL của AWS có thực sự là bước đột phá?
Như chương I, câu trả lời của mình là “No”
Khoảng 3 năm về trước, công ty mình cũng đã áp dụng Zero-ETL bởi xây dựng 1 data virtualized layer (sử dụng Denodo) để data scientist cứ bỏ bất kể files(.csv, .xlsx, .parquet) vào 1 storage bất kỳ (S3, Blob …), nó sẽ tự động hóa tạo table/view trên central data mart cho tất cả các data users trong công ty sử dụng (có kèm luôn data governance framework). Data scientist chẳng cần viết scripts Create/Update/Delete gì cả, data model từ source thay đổi thì các downstream tables cũng tự thay đổi theo. Vì sao tạo data virtualization có giải thích tại đây
Nhưng để mà nói đến Zero-ETL integration, thì người đi đầu trong lĩnh vực này phải nói đến Cinchy khi họ trình làng concept Dataware. Như mình đã giải thích những mặt hạn chế của “copy-based integration“, Cinchy sử dụng phương pháp “zero-copy integration”, ở đây mình không giải thích chi tiết, nhưng bạn có thể tìm hiểu thêm với hình bên dưới
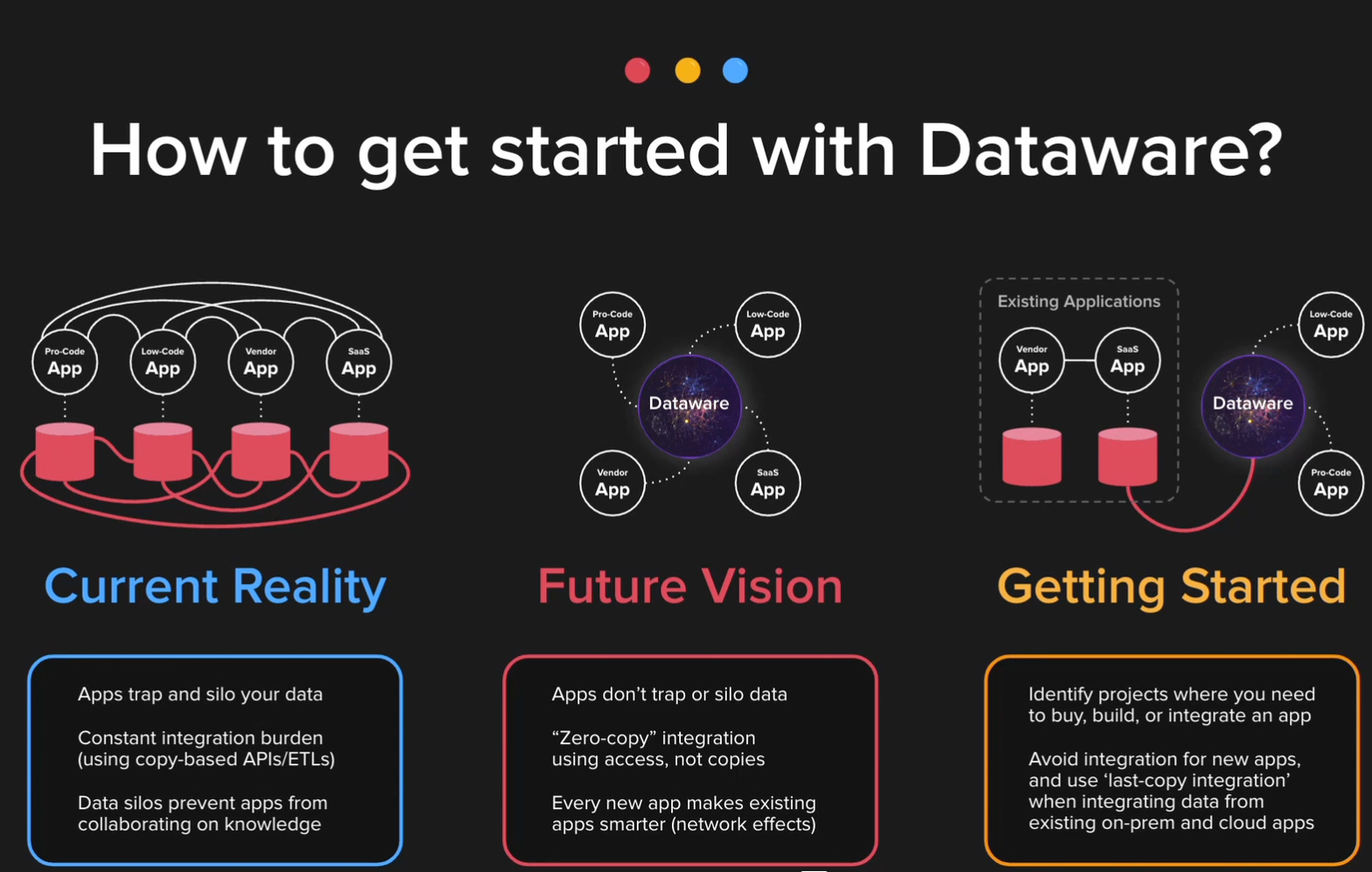
III. Nếu không làm ETL, vậy đây là sự kết thúc role Data Engineer?
Hy vọng đọc đến đây mình đã thuyết phục bạn phần nào việc thay thế ETL pipeline truyền thống bằng Zero-ETL sẽ mất rất nhiều thời gian nữa. Vì thế, role Data Engineer sẽ khó mà kết thúc trong nay mai được. Nhưng vì là người luôn chiều lòng bạn đọc, giả sử đến lúc ETL pipeline có thể bị thay thế hoàn toàn luôn, vậy role Data Engineer có còn tồn tại không? Thế thì mình cho bạn nhìn xuống hình bên dưới nhé, ETL vốn là 1 phần trong rất rất nhiều trọng trách mà 1 Data Engineer phải đảm nhận, vì thế đừng có lo thiếu việc để làm nhé.

Sẵn tiện mình có dự báo luôn, trong tương lai khi data engineering ngày càng phát triển hơn, thì role Data Engineer sẽ phân hóa ra nhiều nhánh với các tên gọi khác nhau. Với khởi đầu là Analytics Engineer và Data Reliability Engineer, hãy cùngđợi xem những điều sắp tới hen
VI. Tóm tắt
Zero-ETL hiện nay cá nhân mình thấy vẫn là trò marketing, khi chưa giải quyết được chữ T trong E-T-L thì selling point rất kém (weak). Zero-EL thì khả thi
Sử dụng Zero-ETL integration trong đúng trường hợp sẽ rất hữu dụng, nhưng đa số với các use-cases hiện nay thì rất hạn chế
Tưởng tượng Zero-ETL như cách con người tiêu hóa thức ăn vậy. Đôi lúc ăn cháo hay đồ lỏng thì nuốt 1 phát tới bụng luôn không sao. Nhưng nếu ăn đồ cứng, to mà không nhai kỹ thì hậu quả tự bạn chịu thôi
Bài đến đây là hết rồi, chúc các bạn vui vẻ. Sau đây mình xin quảng cáo 1 chút nhé:
Nếu bạn thích content của mình, thì hãy follow Trung-Duy Ng để xem chia sẻ về ngành Data và cuộc đời của mình
Than gia group Vietnamese Data Science and Engineering Community in EU để cùng xây dựng cộng đồng data tại EU nhé